
Hello 👋, I’m Hongrui Jia (贾泓睿). I’m a second-year Master’s student at Peking University, advised by Prof. Shikun Zhang and Prof. Wei Ye. My primary research interests lie in building reliable multimodal reasoning systems. I have published several papers at top-tier international AI conferences and journals with total 
📚 Educations
- 2024.09 - 2027.06, MS, Software Engineering, Peking University.
- 2020.09 - 2024.06, BS, Software Engineering, South China University of Technology.
🔬 Research Interests
Building reliable multimodal reasoning systems.
My research focuses on improving the reliability of multimodal reasoning in large multimodal models and agents. My work investigates three closely connected directions: diagnosing failure modes in multimodal reasoning, enforcing reasoning processes grounded in reliable evidence, and enabling targeted capability improvement through diagnostic feedback. Together, these efforts aim to advance multimodal AI systems that can reason reliably in complex, open-world environments.
Diagnosing Failure Modes in Multimodal Reasoning
A key step toward reliable multimodal reasoning is understanding how and why models fail. Multimodal systems often exhibit hallucinations, reasoning drift, and failures in tool interaction, which can lead to unreliable reasoning outcomes. My work develops systematic evaluation frameworks and benchmarks to reveal these hidden weaknesses and to better understand the limits of current multimodal reasoning systems.
Related works: Hal-Eval (ACM MM 2024), OSWorld-MCP (ICLR 2026)
Grounded Multimodal Reasoning
Reliable reasoning requires that reasoning processes remain grounded in multimodal evidence rather than drifting toward purely textual patterns. My work studies mechanisms that strengthen the interaction between perception and reasoning, including improved multimodal representations and training strategies that encourage models to attend to visual evidence during reasoning.
Related works: MaVEn (NeurIPS 2024), SymDPO (CVPR 2025), Decoupled Reasoning and Perception
Capability Improvement through Diagnostic Feedback
Beyond diagnosing and correcting failures, I study how diagnostic insights can guide targeted model improvement. By linking failure analysis with data generation and training strategies, this line of work explores how multimodal reasoning systems can be iteratively improved to address their weaknesses and continually expand their reasoning capabilities.
Related works: Diagnostic-driven Progressive Evolution (DPE)
📝 Publications
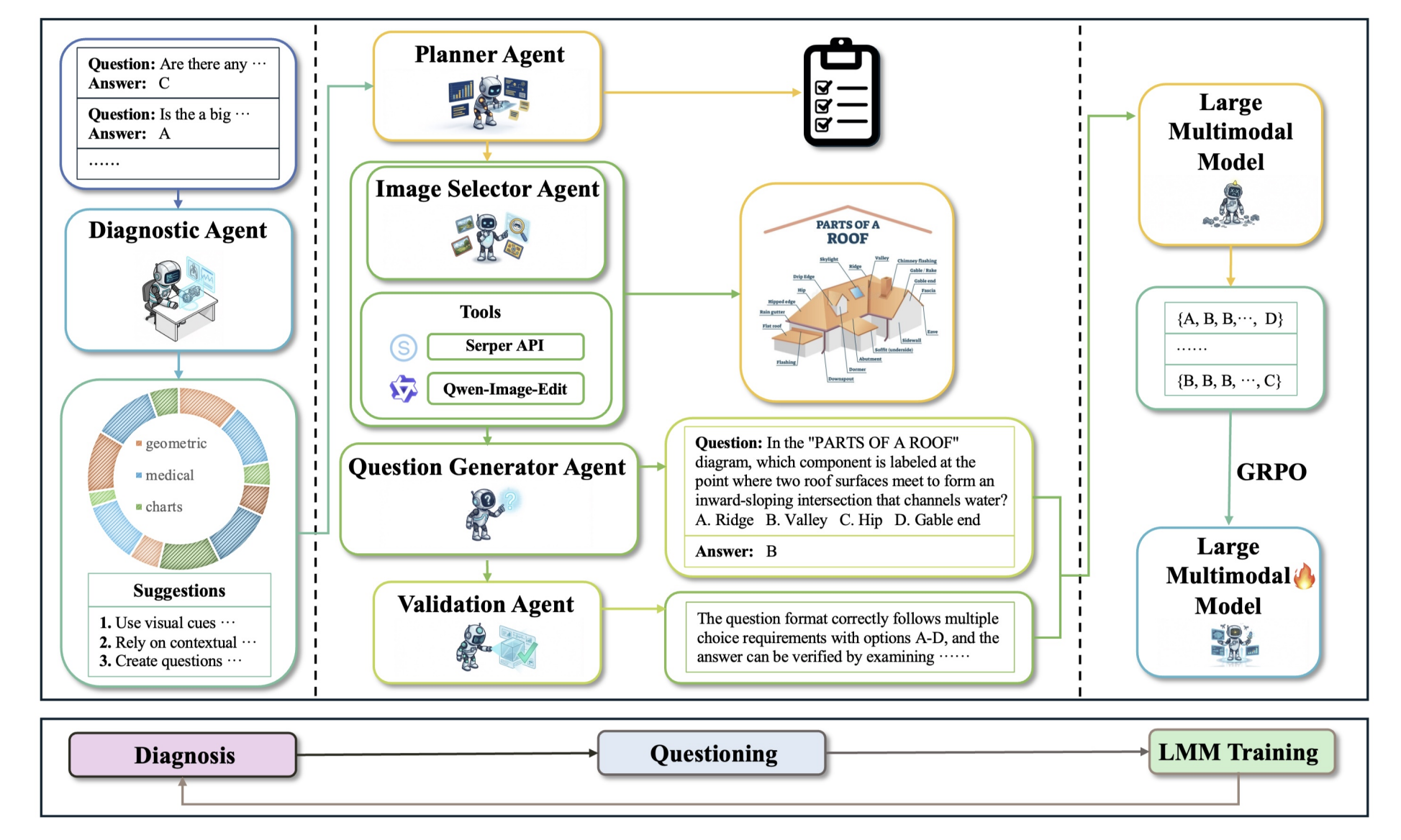
From Blind Spots to Gains: Diagnostic-Driven Iterative Training for Large Multimodal Models
Hongrui Jia, Chaoya Jiang, Shikun Zhang, Wei Ye
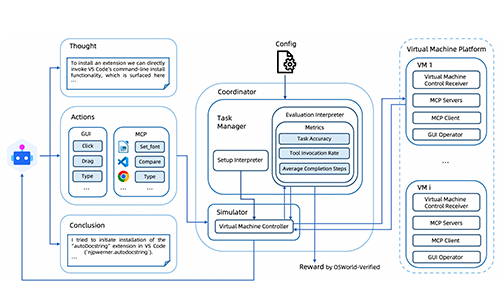
OSWORLD-MCP: BENCHMARKING MCP TOOL INVOCATION IN COMPUTER-USE AGENTS
Hongrui Jia, Jitong Liao, Xi Zhang, Haiyang Xu, Tianbao Xie, Chaoya Jiang, Ming Yan, Si Liu, Wei Ye, Fei Huang
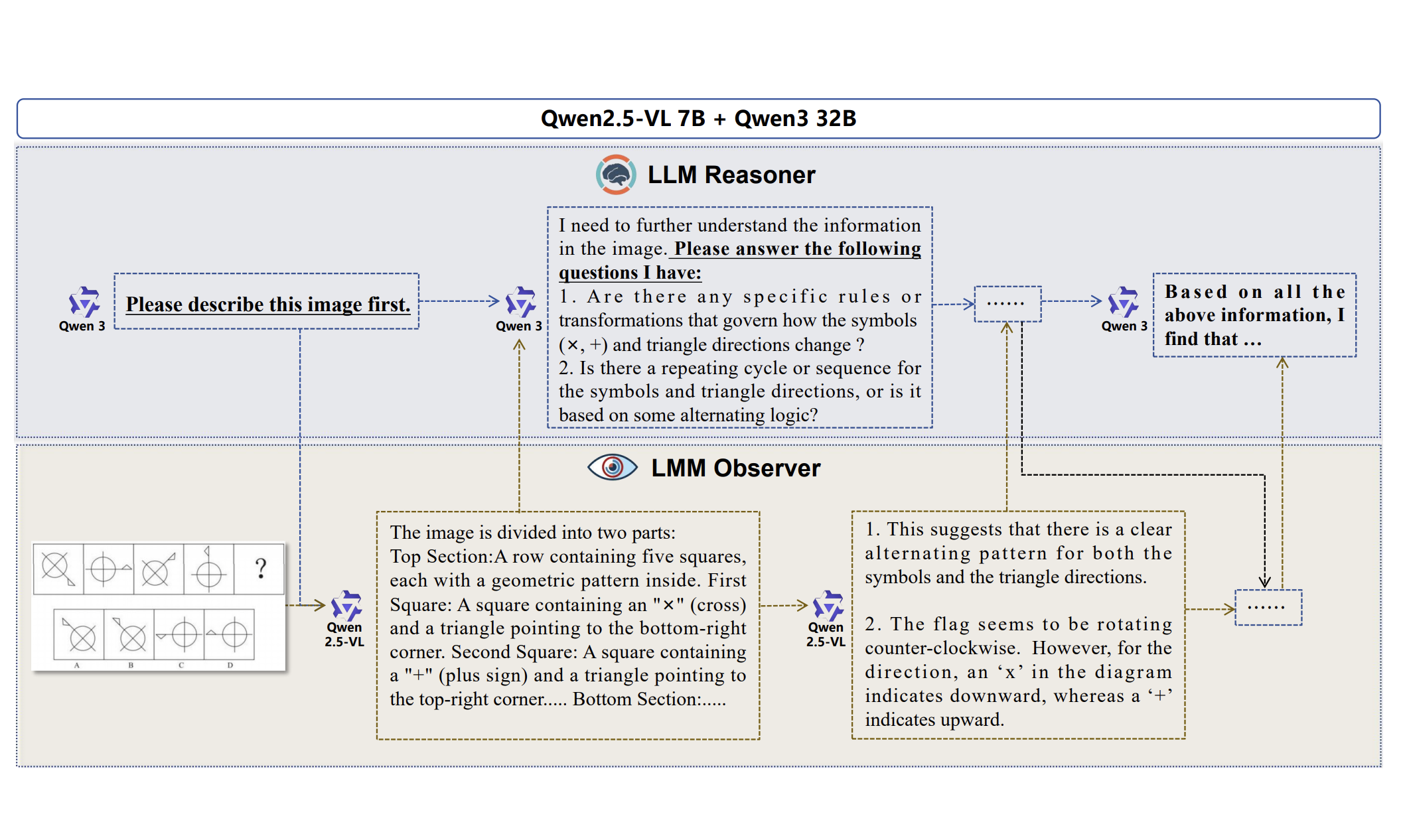
Decoupling Reasoning and Perception: An LLM-LMM Framework for Faithful Visual Reasoning
Hongrui Jia, Chaoya Jiang, Shikun Zhang, Wei Ye
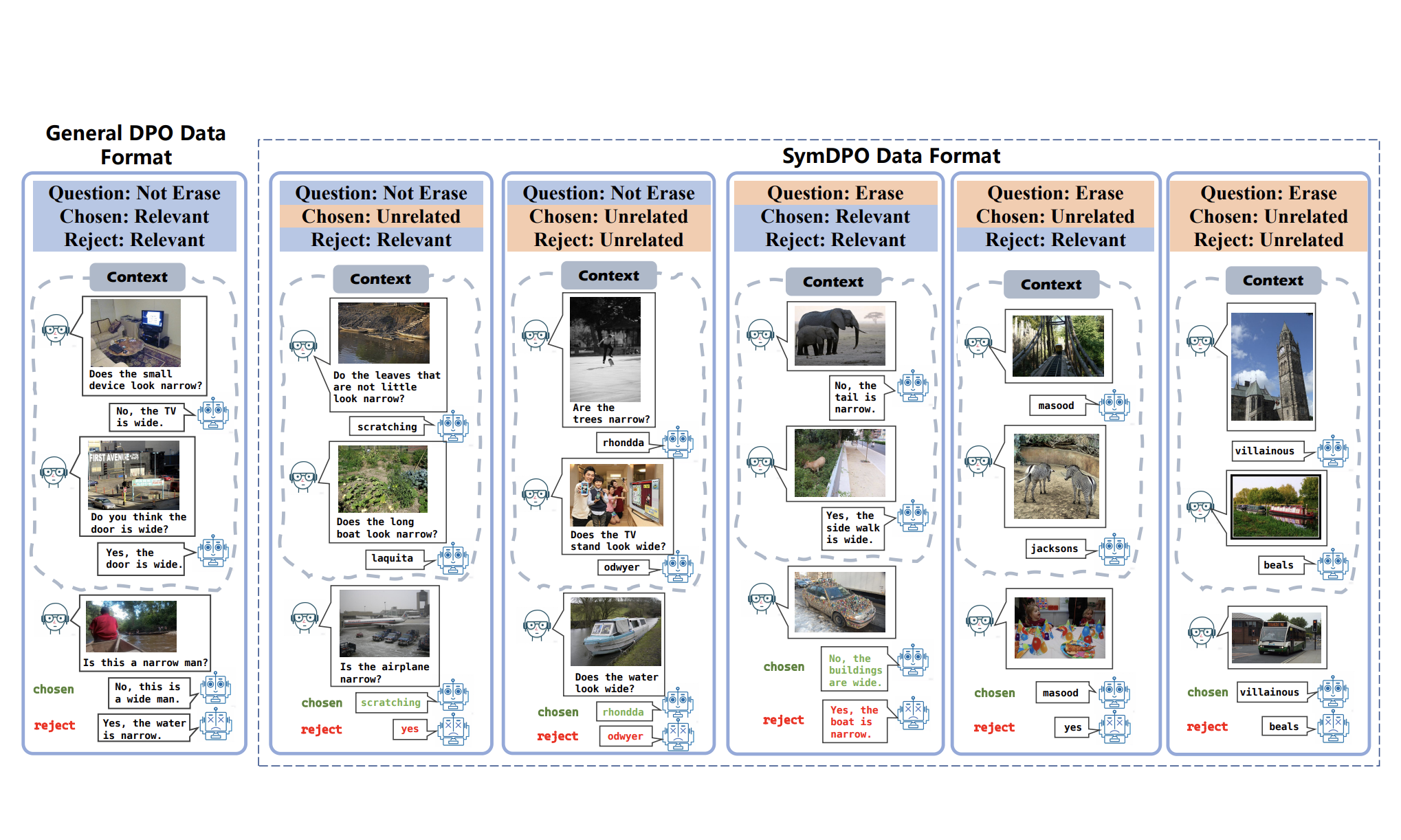
Hongrui Jia, Chaoya Jiang, Haiyang Xu, Wei Ye, Mengfan Dong, Ming Yan, Ji Zhang, Fei Huang, Shikun Zhang
Chaoya Jiang, Hongrui Jia (*Equal Contribution), Haiyang Xu, Wei Ye, Mengfan Dong, Ming Yan, Ji Zhang, Fei Huang, Shikun Zhang

Chaoya Jiang, Hongrui Jia (*Equal Contribution), Mengfan Dong, Wei Ye, Haiyang Xu, Ming Yan, Ji Zhang, Shikun Zhang
🎖 Honors and Awards
- 2025.10 National Scholarship.
- 2021.10 National Scholarship.